METRICS AND MEASUREMENT
Metrics and measurement is comprised of two major bodies of knowledge, both studying the quantitative assessment of performance using test statistics. The first area includes the test measurement (primarily education-oriented), opinion survey, and market research survey industries. The second area is software engineering whereby the technical specifications of computer programs are appraised for execution.
EDUCATION TESTS, OPINION SURVEYS,
AND MARKET RESEARCH
In the education industry, student intelligence measurement is a key concern for several reasons, including resource scarcity and pressure to keep up with a world that's becoming increasingly technological. The market research industry finds corporations striving to reach their customers through advertising and direct contact as well through niche marketing, whereby firms are able to reach consumers by way of preferred select offerings. This increased focus has driven firms to increase their knowledge of their customers and produce or provide services to meet specific consumer demands. Research methodologies used for measuring student learning and consumer preferences and profiles are similar.
The reporting and interpretation of tests and surveys is becoming more of a matter of presentation than content. For example, if a simple spelling test was administered and the number of words correctly spelled was 67, what would this raw score mean? By itself, not much. Questions that would arise include: How many words were asked to be spelled on the test? How many difficult and easy words were there? What is the age and education of the person being tested? Raw scores (absolute standards) typically need to be transformed into a test statistic for the purposes of measurement. Likewise, a survey designed to poll people on their preference for capital punishment will generate varying results depending on who is asked, the circumstances of when the question is asked, and so on. For example, the time period surrounding an emotionally charged event, such as the murder of a child, may cause sentiment in favor of capital punishment to rise. The way capital punishment is carried out (hanging, electric chair, lethal injection, firing squad) can affect public opinion as well. Researching consumer tastes will produce different results depending on the consumer group, season of the year, state of the economy, and so on.
The units of measurement are the test (or survey) scores. There are two major types of scores: norm-referenced scores and content-referenced scores. Norm-referenced scores—which include same group (inter-individual) and growth (intra-individual)norms—measure the raw scores relative to a statistical norm. Same-group norms measure the performance compared to a reference group—the benchmark. Growth norms are used to interpret scores over time, and are relevant when observing an individual or group that is changing because of training, aging, disease progression, etc.
Content-referenced scores provide insight into how specific test questions were answered. Examples of metrics that provide this information are raw, percent correct, and criterion (e.g., pass/fail, healthy/sick, satisfied/unsatisfied) scores.
Of these two types of scores, norm-referenced scores, in general, have become much more popular as opposed to content-referenced scores. Of course, which is the most appropriate depends on the situation.
Another rationale for scales and norms to interpret tests (and surveys) is that the number of questions answered correctly is not necessarily a meaningful measure. First, it assumes each unit (question) is of equal value. Second, it may depend on the purpose (e.g., minimal knowledge or ability). One assumes the test (or survey) results are transferable to other situations (or places) and are therefore generalizable. For example, passing a competency test, such as a driver's license test, denotes competence; that is, you can perform a specific task, such as driving, adequately. Similarly, a marketing survey conducted in San Diego, California, that finds a preference for red-painted cars is more useful if it holds true for people living in Chicago, Atlanta, and elsewhere.
Metrics that may be used to report and interpret test scores include:
- Percent score (or percentage): This is calculated by dividing the number correct by the total number of questions.
- Letter Grade: In education, a letter is often used to denote performance. A, B, C, D, and E represent excellent, good, satisfactory, marginal, and failing performance, respectively. Sometimes letter grades have a plus or minus to create a more precise measure. Letter grades may be used to categorize a percent score, such as 90 percent and above being an A.
- Rank: The relative performance of an individual within a group is placed in descending order from the best (one), to the next best (two), and so on to the worst performance.
- Percentile Rank: This statistic combines the concept of percent and rank whereby the best performance by an individual in a group is 100 percentile and the worst is 0 percentile. For those in between the percentile rank is the percentage of people in the group you outperformed. One hundred less the percentile rank is the percentage of people who did better than that individual.
- Decile Rank: This is similar to percentile score except the precision is in 10 percentile increments.
- Z-Score: As most sample or population distributions fit a bell-shaped normal curve, the raw score is converted into a Z-statistic. This transformation is done by taking the raw score and subtracting the mean and then dividing this difference by the standard deviation.
- T-Score: This is not to be confused with the T-scaled score. The T-score is a variant of the Z-Score, where T = lOz + 50.
- Stanines: Fast becoming a popular metric, as it classifies individuals in a group into categories one through nine. If the group adheres to a normal distribution the stanines match up to the percentile ranks shown in Table 1.
SOFTWARE ENGINEERING METRICS
The impact of computers on business and society increased exponentially in the latter part of the 20th century. Methods of measuring the quality of software programs are continually being developed. Much of the metrics to measure and distinguish software quality focus on conformance to explicit development standards, functional and performance requirements, and features expected of all software. The measurement of software quality can be classified into those variables that can be directly measured (e.g., errors per billion calculations) and indirectly measured (e.g., maintainability).
Important quality factors include the following measures:
- Correctness: The degree to which a program meets its specification and satisfies the client's goals.
- Efficiency: The amount of computing resources and code needed by the program to perform its tasks.
- Flexibility: The effort needed to change a program.
- Integrity: The ability to prevent unauthorized access to the program.
- Maintainability: The effort needed to find and fix program errors.
- Interoperability: The effort needed to attach one system to another system.
- Portability: The effort needed to transfer the program from hardware to hardware and/or to another software system.
-
Reliability: The degree to which a program performs its function to
expectations.
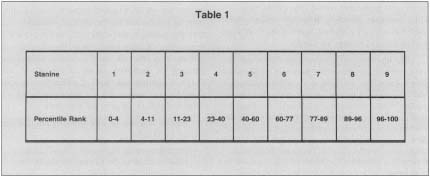 Table 1
Table 1Stanine 1 2 3 4 5 6 7 8 9 Percentile Rank 0-4 4-11 11-23 23-40 40-60 60-77 77-89 89-96 96-100 - Reusability: The extent to which the program, partially or wholly, can be used in other applications.
- Testability: The extent of testing needed to verify that the program performs satisfactorily.
- Usability: The amount of training required to learn how to use the software.
The metrics to grade (on a scale of 0 [low] to [high]) the previous measures are as follows:
- Auditability: The ease of compliance to standards can be audited.
- Accuracy: The precision of calculations.
- Communication Commonality: The extent to which standard protocols, interfaces, and bandwidth are employed.
- Completeness: The extent to which the function is achieved.
- Conciseness: The brevity of the program measured by lines of code.
- Consistency: The use of uniform documentation and design methods.
- Data Commonality: The use of standard data types.
- Error Tolerance: The harm that occurs when errors are encountered.
- Execution Efficiency: The run-time program performance.
- Expandability: The extent to which procedural design and data can be extended.
- Generality: The breadth of program applications.
- Hardware Independence: The degree to which the hardware and software are operationally separated.
- Instrumentation: The extent to which the program evaluates its own functioning and identifies errors.
- Modularity: The functional independence of program components.
- Operability: The degree of complexity in operating the software.
- Security: The ability to protect data and programs.
- Self-Documentation: The extent to which relevant documentation is provided.
- Simplicity: The ease with which the program can be understood.
- Software System Independence: The extent to which the software is independent of nonstandard features such as program language and operating system.
- Traceability: The capacity to trace a program design component to its requirements.
- Training: The amount of assistance provided by the software to new users.
As both software and hardware engineering evolve, new metrics and measurements will be created to evaluate the performance quality.
The purposes of the measurement of the metrics are to help evaluate the software models, indicate the complexity of the procedural designs and source code, and aid in the construction of more testing. This measurement process follows five steps:
- Formulation of metrics appropriate to evaluate the software.
- Collection of data needed to compute the chosen metrics.
- Analysis and calculation of metrics.
- Interpretation of the metrics to provide understanding.
- Feedback given to the system designers of the software.
In these ways, metrics and measurement can provide a quantifiable gauge of quality for software, facilitating the improvement of the product by the software engineer.
[ Raymond A. K. Cox ]
FURTHER READING:
Ebel, R. L. Essentials of Educational Measurement. Englewood Cliffs, NJ: Prentice-Hall, 1979.
Grady, R. B. Practical Software Metrics for Project Management and Process Improvement. Englewood Cliffs, NJ: Prentice-Hall, 1992.
Lorenz, M., and J. Kidd. Object-Oriented Software Metrics. Englewood Cliffs, NJ: Prentice Hall, 1994.
Sheppard, M. Software Engineering Metrics. New York: McGraw-Hill, 1992.
Comment about this article, ask questions, or add new information about this topic: