DATA PROCESSING
AND DATA MANAGEMENT

Data processing and data management are critical components of business organizations.
DATA PROCESSING
Data processing refers to the process of performing specific operations on a set of data or a database. A database is an organized collection of facts and information, such as records on employees, inventory, customers, and potential customers. As these examples suggest, numerous forms of data processing exist and serve diverse applications in the business setting.
Data processing primarily is performed on information systems, a broad concept that encompasses computer systems and related devices. At its core, an information system consists of input, processing, and output. In addition, an information system provides for feedback from output to input. The input mechanism (such as a keyboard, scanner, microphone, or camera) gathers and captures raw data and can be either manual or automated. Processing, which also can be accomplished manually or automatically, involves transforming the data into useful outputs. This can involve making comparisons, taking alternative actions, and storing data for future use. Output typically takes the form of reports and documents that are used by managers. Feedback is utilized to make necessary adjustments to the input and processing stages of the information system.
The processing stage is where management typically exerts the greatest control over data. It also is the point at which management can derive the most value from data, assuming that powerful processing tools are available to obtain the intended results. The most frequent processing procedures available to management are basic activities such as segregating numbers into relevant groups, aggregating them, taking ratios, plotting, and making tables. The goal of these processing activities is to turn a vast collection of facts into meaningful nuggets of information that can then be used for informed decision making, corporate strategy, and other managerial functions.
DATA AND INFORMATION.
Data consist of raw facts, such as customer names and addresses. Information is a collection of facts organized in such a way that it has more value beyond the facts themselves. For example, a database of customer names and purchases might provide information on a company's market demographics, sales trends, and customer loyalty/turnover.
Turning data into information is a process or a set of logically related tasks performed to achieve a defined outcome. This process of defining relationships between various data requires knowledge. Knowledge is the body or rules, guidelines, and procedures used to select, organize, and manipulate data to make it suitable for specific tasks. Consequently, information can be considered data made more useful through the application of knowledge. The collection of data, rules, procedures, and relationships that must be followed are contained in the knowledge base.
CHARACTERISTICS OF VALUABLE INFORMATION.
In order for information to be valuable it must have the following characteristics, as adapted from Ralph M. Stair's book, Principles of Information Systems:
- Accurate. Accurate information is free from error.
- Complete. Complete information contains all of the important facts.
- Economical. Information should be relatively inexpensive to produce.
- Flexible. Flexible information can be used for a variety of purposes, not just one.
- Reliable. Reliable information is dependable information.
- Relevant. Relevant information is important to the decision-maker.
- Simple. Information should be simple to find and understand.
- Timely. Timely information is readily available when needed.
- Verifiable. Verifiable information can be checked to make sure it is accurate.
DATA MANAGEMENT
Data are organized in a hierarchy that begins with the smallest piece of data used by a computer—for purposes of this discussion, a single character such as a letter or number. Characters form fields such as names, telephone numbers, addresses, and purchases. A collection of fields makes up a record. A collection of records is referred to as a file. Integrated and related files make up a database.
An entity is a class of people, objects, or places for which data are stored or collected. Examples include employees and customers. Consequently, data are stored as entities, such as an employee database and a customer database. An attribute is a characteristic of an entity. For example, the name of a customer is an attribute of a customer. A specific value of an attribute is referred to as a data item. That is, data items are found in fields.
The traditional approach to data management consists of maintaining separate data files for each application. For example, an employee file would be maintained for payroll purposes, while an additional employee file might be maintained for newsletter purposes. One or more data files are created for each application. However, duplicated files results in data redundancy. The problem with data redundancy is the possibility that updates are accomplished in one file but not in another, resulting in a lack of data integrity. Likewise, maintaining separate files is generally inefficient because the work of updating and managing the files is duplicated for each separate file that exists. To overcome potential problems with traditional data management, the database approach was developed.
The database approach is such that multiple business applications access the same database. Consequently, file updates are not required of multiple files. Updates can be accomplished in the common database, thus improving data integrity and eliminating redundancy. The database approach provides the opportunity to share data, as well as information sources. Additional software is required to implement the database approach to data management. A database management system (DBMS) is needed. A DBMS consists of a group of programs that are used in an interface between a database and the user, or between the database and the application program. Advantages of the database approach are presented in Table 1. Disadvantages of the database approach are presented in Table 2.
DATA ORGANIZATION.
Data organization is critical to optimal data use. Consequently, it is important to organize data in such a manner as to reflect business operations and practices. As such, careful consideration should be given to content, access, logical structure, and physical organization. Content refers to what data are going to be collected. Access refers to the users that data are provided to when appropriate. Logical structure refers to how the data will be arranged. Physical structure refers to where the data will be located.
One tool that database designers use to show the logical relationships among data is a data model, which is a map or diagram of entities and their relationships. Consequently, data modeling requires a thorough understanding of business practices and what kind of data and information is needed.
DATABASE MODELS.
The structure of the relationships in most databases follows one of three logical database models: hierarchical, network, and relational.
A hierarchical database model is one in which the data are organized in a top-down or inverted tree-like structure. This type of model is best suited for situations where the logical relationships between data can be properly represented with the one-parent-many-children approach.
A network model is an extension of the hierarchical database model. The network model has an owner-member relationship in which a member may have many owners, in contrast to a one-to-many-relationship.
A relational model describes data using a standard tabular format. All data elements are placed in two-dimensional tables called relations, which are the equivalent of files. Data inquiries and manipulations can be made via columns or rows given specific criteria.
Network database models tend to offer more flexibility than hierarchical models. However, they are more difficult to develop and use because of relationship complexity. The relational database model offers the most flexibility, and was very popular during the early 2000s.
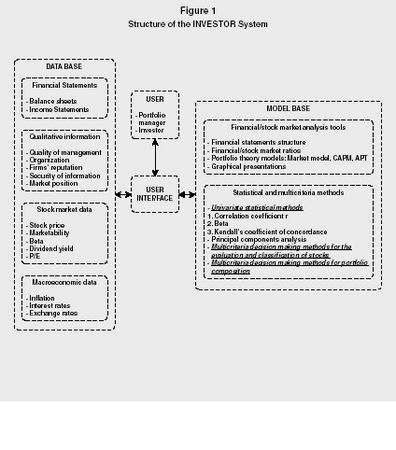
Structure of the INVESTOR System
DATABASE MANAGEMENT SYSTEMS.
As indicated previously, a database management system (DBMS) is a group of programs used as an interface between a database and an applications program. DBMSs are classified by the type of database model they support. A relational DBMS would follow the relational model, for example. The functions of a DBMS include data storage and retrieval, database modifications, data manipulation, and report generation.
A data definition language (DDL) is a collection of instructions and commands used to define and describe data and data relationships in a particular database. File descriptions, area descriptions, record descriptions, and set descriptions are terms the DDL defines and uses.
A data dictionary also is important to database management. This is a detailed description of the structure and intended content in the database. For example, a data dictionary might specify the maximum number of characters allowed in each type of field and whether the field content can include numbers, letters, or specially formatted content such as dates or currencies. Data dictionaries are used to provide a standard definition of terms and data elements, assist programmers in designing and writing programs, simplify database modifications, reduce data redundancy,

Disadvantage of the Database Approach
| Disadvantages | Explanation |
| Relative high cost of purchasing and operating a DBMS in a mainframe operating environment | Some mainframe DBMSs can cost millions of dollars. |
| Specialized staff | Additional specialized staff and operating personnel may be needed to implement and coordinate the use of the database. It should be noted, however, that some organizations have been able to implement the database approach with no additional personnel. |
| Increased vulnerability | Even though databases offer better security because security measures can be concentrated on one system, they also may make more data accessible to the trespasser if security is breached. In addition, if for some reason there is a failure in the DBMS, multiple application programs are affected. |
increase data reliability, and decrease program development time.
The choice of a particular DBMS typically is a function of several considerations. Economic cost considerations include software acquisition costs, maintenance costs, hardware acquisition costs, database creation and conversion costs, personnel costs, training costs, and operating costs.
Most DBMS vendors are combining their products with text editors and browsers, report generators, listing utilities, communication software, data entry and display features, and graphical design tools. Consequently, those looking for a total design system have many choices.
DATA WAREHOUSING.
Data warehousing involves taking data from a main computer for analysis without slowing down the main computer. In this manner, data are stored in another database for analyzing trends and new relationships. Consequently, the data warehouse is not the live, active system, but it is updated daily or weekly. For example, Wal-Mart uses a very large database (VLDB) that is 4 trillion bytes (terabytes) in size. Smaller parts of this database could be warehoused for further analysis to avoid slowing down the VLDB.
FUTURE TRENDS.
A private database is compiled from individual consumer or business customer names and addresses maintained by a company for use in its own marketing efforts. Such a database may have originated as a public database, but typically once the company begins adding or removing information it is considered a private database. By contrast, public databases are those names, addresses, and data that are complied for resale in the list rental market. This is publicly available data (i.e., any business can purchase it on the open market) rather than lists of specific customers or targets.
However, a new trend is combining features of the two approaches. Cooperative databases are compiled by combining privately held response files of participating companies so that costs are shared. Many consider this to be a future trend, such that virtually all catalog marketers, for example, would use cooperative databases.
Geographic Information Systems (GIS) are becoming a growing area of data management. GIS involves the combining demographic, environmental, or other business data with geographic data. This can involve road networks and urban mapping, as well as consumer buying habits and how they relate to the local geography. Output is often presented in a visual data map that facilitates the discovery of new patterns and knowledge.
Customer Resource Management (CRM) is another area where data process and data management is deeply involved. CRM is a set of methodologies and software applications for managing the customer relationship. CRM provides the opportunity for management, salespeople, marketers, and potentially even customers, to see sufficient detail regarding customer activities and contacts. This allows companies to provide other possible products or useful services, as well as other business options. Security of this information is of significant concern on both sides of the equation.
SEE ALSO: Computer Networks ; Computer Security
Hal P. Kirkwood , Jr.
FURTHER READING:
Chu, Margaret Y. Blissful Data: Wisdom and Strategies for Providing Meaningful, Useful, and Accessible Data for All Employees. New York: American Management Association, 2003.
Churchill, Gilbert A. Marketing Research: Methodological Foundations. 8th ed. Cincinnati, OH: South-Western College Publishing, 2001.
Stair, Ralph M. Principles of Information Systems: A Managerial Approach. 4th ed. Cambridge, MA: Course Technology, 1999.
Wang, John. Data Mining: Opportunities and Challenges. Hershey, PA: Idea Group Publishing, 2003.
White, Ken. "DBMS Past, Present, and Future." Dr. Dobb's Journal 26, no. 8 (2001): 21–26.
Comment about this article, ask questions, or add new information about this topic: