DECISION TREE
A decision tree is a diagram that a decision maker can create to help select the best of several alternative courses of action. The primary advantage of a decision tree is that it assigns exact values to the outcomes of different actions, thus minimizing the ambiguity of complicated decisions. Because they map out an applied, real-world logical process, decision trees are particularly important to building "smart" computer applications like expert systems. They are also used to help illustrate and assign monetary values to alternative courses of action that management may take.
A decision tree represents a choice or an outcome with a fork, or branch. Several branches may extend from a single point, representing several different alternative choices or outcomes. There are two types of forks: (1) a decision fork is a branch where the decision maker can choose the outcome; and (2) a chance or event fork is a branch where the outcome is controlled by chance or external forces. By convention, a decision fork is designated in the diagram by a square, while a chance fork is usually represented by a circle. It is the latter category of data, when associated with a probability estimate, that makes decision trees useful tools for quantitative analysis of business problems.
A decision tree emanates from a starting point at one end (usually at the top or on the left side) through a series of branches, or nodes, until two or more final results are reached at the opposite end. At least one of the branches leads to a decision fork or a chance fork. The diagram may continue to branch as different options and chances are diagrammed. Each branch is assigned an outcome and, if chance is involved, a probability of occurrence.
EXAMPLE 1
A decision maker may determine that the chance of drilling an oil well that generates $100,000 (outcome) is 25 percent (probability of occurrence). To solve the decision tree, the decision maker begins at the right hand side of the diagram and works toward the initial decision branch on the left. The value of different outcomes is derived by multiplying the probability by the expected outcome; in this example, the value would be $25,000 (0.25 x $100,000). The values of all the outcomes emanating from a chance fork are combined to arrive at a total value for the chance fork. By continuing to work backwards through the chance and decision forks, a value can eventually be assigned to each of the alternatives emanating from the initial decision fork.
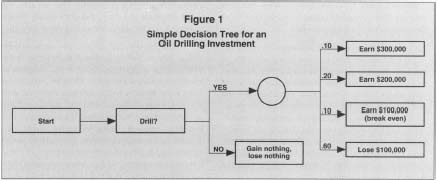
In the rudimentary example below, a company is trying to determine whether or not to drill an oil well. If it decides not to drill the well, no money will be made or lost. Therefore, the value of the decision not to drill can immediately be assigned a sum of zero dollars.
If the decision is to drill, there are several potential outcomes, including (1) a 10 percent chance of getting $300,000 in profits from the oil; (2) a 20 percent chance of extracting $200,000 in profits; (3) a 10 percent chance of wresting $100,000 in profits from the well; and (4) a 60 percent chance that the well will be dry and post a loss of $100,000 in drilling
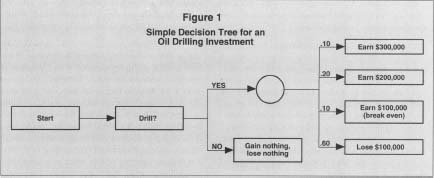
Simple Decision Tree for an
Oil Drilling Investment
For the purposes of demonstration, suppose that the chance of hitting no oil was increased from 60 percent to 70 percent, and the chance of gleaning $300,000 in profits was reduced from ten percent to zero. In that case, the dollar value of the decision to drill would fall to -$20,000. A profit-maximizing decision maker would then elect to not drill the well. The effect of this relatively small change in the probability calculation underscores decision trees' dependence on accurate information, which often may not be available.
EXAMPLE 2
Unlike the hypothetical oil drilling decision, which essentially involved making one choice based on the likelihood of several outcomes, many corporate decisions involve making a more elaborate series of decisions. Consider a bank's decision of whether to loan money to a consumer. A decision tree might be used in a few different ways to aid this multistep process. In the simplest case, the tree might codify the bank's assessment criteria for identifying qualified applicants. Figure 2 illustrates what such a criteria process might look like in a decision tree. This simple tree requires the applicant to meet certain standards (job stability, assets, cash flow) at each stage; it assumes that the minimum standards are effective predictors of success.
A more sophisticated decision tree, possibly implemented through a custom software application, might use data from past borrowers—both reliable and unreliable—to predict the overall likelihood that the applicant is worth the risk. Such a system would allow greater flexibility to identify applicants who may not appear to be strong candidates on one or two criteria, but are statistically likely to be reliable borrowers, and therefore, profitable investments for the bank. Theoretically, this system could identify borrowers who don't meet the traditional, minimum-standard criteria, but who are statistically less likely to default than applicants who do meet all of the minimum
Simple Decision Tree for a Loan Application Process
FURTHER READING:
Ables, Geoffrey. "Predictive Modeling for Non-Statisticians." Target Marketing, March 1997.
Coles, Susan, and Jennifer Rowley. "Revisiting Decision Trees." Management Decision, December 1995.