DECISION RULES
AND DECISION ANALYSIS
A decision rule is a logical statement of the type "if [condition], then [decision]." The following is an example of a decision rule experts might use to determine an investment quality rating:
If the year's margin is at least 4.27 percent and the year's ratio of shareholder funds to fixed assets is at least 35.2 percent, then the class of rating is at least lower investment grade (LIG).
The condition in this decision rule is "the year's margin is at least 4.27 percent and the year's ratio of shareholder funds to fixed assets is at least 35.2 percent," while "the class of rating is at least lower investment grade" is the decision part of the rule.
Decision rules give a synthetic, easily understandable, and generalized representation of the knowledge contained in a data set organized in an information table. The table's rows are labeled by objects, whereas columns are labeled by attributes; entries in the body of the table are thus attribute values. If the objects are exemplary decisions given by a decision maker, then the decision rules represent the preferential attitude of the decision maker and enable understanding of the reasons for his or her preference.
People make decisions by searching for rules that provide good justification of their own choices. However, a direct statement of decision rules requires a great cognitive effort from the decision maker, who typically is more confident making exemplary decisions than explaining them. For this reason, the idea of inferring preference models in terms of decision rules from exemplary decisions provided by the decision maker is very attractive. The induction of rules from examples is a typical approach of artificial intelligence. It is concordant with the principle of posterior rationality, and with aggregation-disaggregation logic. The recognition of the rules by the decision maker justifies their use as a powerful decision support tool for decision making concerning new objects.
There are many applications of decision rules in business and finance, including:
- Credit card companies use decision rules to approve credit card applications.
- Retailers use associative rules to understand customers' habits and preferences (market basket analysis) and apply the finding to launch effective promotions and advertising.
- Banks use decision rules induced from data about bankrupt and non-bankrupt firms to support credit granting decisions.
- Telemarketing and direct marketing companies use decision rules to reduce the number of calls made and increase the ratio of successful calls.
Other applications of decision rules exist in the airline, manufacturing, telecommunications, and insurance industries.
DESCRIBING AND COMPARING
INFORMATION ATTRIBUTES
The examples (information) from which decision rules are induced are expressed in terms of some characteristic attributes. For instance, companies could be described by the following attributes: sector of activity, localization, number of employees, total assets, profit, and risk rating. From the viewpoint of conceptual content, attributes can be of one of the following types:
- Qualitative attributes (symbolic, categorical, or nominal), including sector of activity or localization
- Quantitative attributes, including number of employees or total assets
- Criteria or attributes whose domains are preferentially ordered, including profit, because a company having large profit is preferred to a company having small profit or even loss
The objects are compared differently depending on the nature of the attributes considered. More precisely, with respect to qualitative attributes, the objects are compared on the basis of an indiscernibility relation: two objects are indiscernible if they have the same evaluation with respect to the considered attributes. The indiscernibility relation is reflexive (i.e., each object is indiscernible with itself), symmetric (if object A is indiscernible with object B, then object B also is indiscernible with object A), and transitive (if object A is indiscernible with object B and object B is indiscernible with object C, then object A also is indiscernible with object C). Therefore, the indiscernibility relation is an equivalence relation.
With respect to quantitative attributes, the objects are compared on the
basis of a similarity relation. The similarity between objects can be
defined in many different ways. For example, if the evaluations with
respect to the considered attribute are positive, then the following
statement may define similarity:
For instance, with respect to the attribute "number of
employees," fixing a threshold at 10 percent, Company A having
2,710 employees is similar to Company B having 3,000 employees. Similarity
relation is reflexive, but neither symmetric nor transitive; the abandon
of the transitivity requirement is easily justifiable, remembering, for
example, Luce's paradox of the cups of tea (Luce, 1956). As for the
symmetry, one should notice that the proposition
y
R
x,
which means "
y
is similar to
x,
" is directional; there is a subject
y
and a referent
x,
and in general this is not equivalent to the proposition "
x
is similar to
y.
"
With respect to criteria, the objects are compared on the basis of a dominance relation built using out-ranking relations on each considered criterion: object A outranks object B with respect to a given criterion if object A is at least as good as object B with respect to this criterion; if object A outranks object B with respect to all considered criteria then object A dominates object B. An outranking relation can be defined in many different ways. Oftentimes, it is supposed that outranking is a complete preorder (i.e., transitive and strongly complete). For each couple of objects, say object A and object B, at least one of the following two conditions is always verified: object A outranks object B and/or object B outranks object A. A dominance relation, built on the basis of the outranking relation being a complete preorder, is a partial pre-order (i.e., it is reflexive and transitive, but in general not complete).
DECISION RULE SYNTAX
The syntax of decision rules is different according to the specific decision problem. The following decision problems are most frequently considered:
- Classification
- Sorting
- Choice
- Ranking
Following is a presentation of the syntax of decision rules considered within each one of the above decision problems.
CLASSIFICATION.
Classification concerns an assignment of a set of objects to a set of predefined but non-ordered classes. A typical example of classification is the problem of market segmentation; in general there is no preference order between the different segments. The objects are described by a set of (regular) attributes that can be qualitative or quantitative. The syntax of decision rules specifies the condition part and the decision part.
With respect to the condition part, the following types of decision rules can be distinguished:
- Decision rules based on qualitative attributes: "if the value of attribute q 1 is equal to r q 1 and the value of attribute q 2 is equal to r q 2 and … and the value of attribute q p is equal to r qp , then [decision]," where r q 1 , r q 2 , …, r qp are possible values of considered attributes.
- Decision rules based on quantitative attributes: "if the value of attribute q 1 is similar to r q 1 and the value of attribute q 2 is similar to r q 2 and … and the value of attribute q p is similar to r qp , then [decision]," where r q 1 , r q 2 , …, r qp are possible values of considered attributes.
- Decision rules based on qualitative and quantitative attributes: "if the value of attribute q 1 is equal to r q 1 and the value of attribute q 2 is equal to r q 2 and … and the value of attribute q t is equal to r qt and the value of attribute q t +1 is similar to r qt +1 and the value of attribute q t +2 is similar to r qt +2 and … and the value of attribute q p is similar to r qp , then [decision]," where q 1 q 2 …, q t are qualitative attributes, q t +1 , q t +2 , …, q p are quantitative attributes, and r q 1 , r q 2 , …, r qp are possible values of considered attributes.
With respect to the decision part, the following types of decision rules can be distinguished:
- Exact decision rule: "if [condition], then the object belongs to Y j ," where Y j is a decision class of the considered classification.
- Approximate decision rule: "if [condition], then the object belongs to Y j 1 or Y j 2 or … Y jk ," where Y j 1 , Y j 2 , …, Y jk are some decision classes of the considered classification.
- Possible decision rule: "if [condition], then the object could belong to Y j ," where Y j is a decision class of the considered classification.
SORTING.
Sorting concerns an assignment of a set of objects to a set of predefined and preference ordered classes. The classes are denoted by Cl 1 Cl 2 and so on, and we suppose that they are preferentially ordered such that the higher the number the better the class (i.e., the elements of class Cl 2 have a better comprehensive evaluation than the elements of class Cl 1 the elements of class Cl 3 have a better comprehensive evaluation than the elements of class Cl 2 and so on. For example, in a problem of bankruptcy risk evaluation, Cl 1 is the set of unacceptable-risk firms, Cl 2 is a set of high-risk firms, Cl 3 is a set of medium-risk firms, and so on. The objects are evaluated by a set of attributes that generally include criteria and qualitative and/or quantitative (regular) attributes. The syntax of the condition depends on the type of attributes used for object description. If there are criteria only, then the following types of decision rules can be distinguished:
- Exact D≥ decision rule: "if evaluation with respect to criterion q 1 is at least as good as r q 1 and evaluation with respect to criterion q 2 is at least as good as r q 2 and … evaluation with respect to criterion q p is at least as good as r qp , then the object belongs to at least class t, " where r q 1 , r q 2 , …, r qp are possible values of considered criteria.
- Exact D≤ decision rule: "if evaluation with respect to criterion q 1 is at most as good as r q 1 and evaluation with respect to criterion q 2 is at most as good as r q 2 and … evaluation with respect to criterion q p is at most as good as r qp , then the object belongs to at most class t, " where r q 1 , r q 2 , …, r qp are possible values of considered criteria.
- Approximate D≥≤ decision rule: "if evaluation with respect to criterion q 1 is at least as good as r q 1 and evaluation with respect to criterion q 2 is at least as good as r q 2 and … evaluation with respect to criterion q h is at least as good as r qh and evaluation with respect to criterion q h +1 is at most as good as r qh +1 and evaluation with respect to criterion q h +2 is at most as good as r qh +2 and … evaluation with respect to criterion q p is at most as good as r qp , then the object belongs to at least class t and at most to class t " where criteria q 1 q 2 …, q k are not necessarily different from q k +1 , q k +2 , …, q p and r q 1 , r q 2 , …, r qp are possible values of considered criteria.
- Possible D≥ decision rule: "if evaluation with respect to criterion q 1 is at least as good as r q 1 and evaluation with respect to criterion q 2 is at least as good as r q 2 and … evaluation with respect to criterion q p is at least as good as r qp , then the object could belong to at least class t, " where r q 1 , r q 2 , …, r qp are possible values of considered criteria.
- Possible D≤ decision rule: "if evaluation with respect to criterion q 1 is at most as good as r q 1 and evaluation with respect to criterion q 2 is at most as good as r q 2 and … evaluation with respect to criterion q p is at most as good as r qp , then the object could belong to at most class t, " where r q 1 , r q 2 , …, r qp are possible values of considered criteria.
CHOICE AND RANKING.
Choice concerns selecting a small subset of best objects from a larger set, while ranking concerns ordering objects of a set from the best to the worst. In these two decision problems, the objects are evaluated by criteria and the decision is based on pairwise (relative) comparison of objects rather than on absolute evaluation of single objects. In other words, in these two cases the decision rules relate preferences on particular criteria with a comprehensive preference. The preferences can be expressed on cardinal scales or on ordinal scales: the former deal with strength of preferences and use relations like indifference, weak preference, preference, strong preference, absolute preference, while for the later the strength is meaningless.
Given objects x, y, w and z, and using a cardinal scale of preference, it always is possible to compare the strength of preference of x over y with the strength of preference of w over z and say whether the preference of x over y is stronger than, equal to, or weaker than the preference of w over z. Using an ordinal scale, the strengths of preference can be compared only if, with respect to the considered criterion, object x is at least as good as w and z is at least as good as y. Given an example of car selection, for any decision maker car x, with a maximum speed 200 kilometers per hour (124.28 miles per hour) is preferred to car y, with a maximum speed of 120 kilometers per hour (74.57 miles per hour) at least as much as car w, with a maximum speed 170 kilometers per hour (105.64 miles per hour) is preferred to car z, with a maximum speed 140 kilometers per hour (87 miles per hour). This is because it is always preferable to pass from a smaller maximum speed (car y versus z ) to a larger maximum speed (car x versus w ). The syntax of the decision rules in the choice and ranking problems depends on the distinction between cardinal and ordinal criteria:
- Exact D≥ decision rule: "if with respect to cardinal criterion q 1, x is preferred to y with at least strength h ( q 1) and … and with respect to cardinal criterion qe, x is preferred to y with at least strength h ( qe ) and with respect to ordinal criterion qe + 1, evaluation of x is at least as good as r qe +1 and evaluation of y is at most as good as s qe +1 and … and with respect to ordinal criterion q p +1 , evaluation of x is at least as good as r qp +1 and evaluation of y is at most as good as s qp +1 , then x is at least as good as y, " where h ( q 1), …, h ( qe ) are possible strengths of preferences of considered criteria and r qe +1 , …, r qp , and s qe +1 , …, s qp are possible values of considered criteria. A more concise illustration: "if with respect to comfort (cardinal criterion) car x is at least strongly preferred to car y and car x has a maximum speed (ordinal criterion) of at least 200 kilometers per hour (124.28 miles per hour) and car y has a maximum speed of 160 kilometers per hour (99.42 miles per hour), then car x is at least as good as car y. "
- Exact D≤ decision rule: "if with respect to cardinal criterion q 1, x is preferred to y with at most strength h ( q 1) and … and with respect to cardinal criterion qe, x is preferred to y with at most strength h ( qe ) and with respect to ordinal criterion qe + 1, evaluation of x is at most as good as r qe +1 and evaluation of y is at least as good as s qe +1 and … and with respect to ordinal criterion qp, evaluation of x is at most as good as r qp and evaluation of y is at least as good as s qp +1 , then x is not at least as good as y, " where h ( q 1), …, h ( qe ) are possible strengths of preferences of considered criteria and r qe +1, …, r qp , and s q e+1 , …, s qp are possible values of considered criteria. An example of a D≤ decision rule: "if with respect to aesthetics (cardinal criterion) car x is at most indifferent with car y and car x consumes (ordinal criterion) at most 7.2 liters (1.90 gallons) of fuel per 100 kilometers (62.14 miles) and car y consumes at least at 7.5 liters (1.98 gallons) of fuel per 100 kilometers (62.14 miles), then car x is at most as good as car y. "
- Approximate D≥≤ decision rule: the "if" condition has the syntax composed of the "if" parts of the D≥ rule and the D≤ rule. The "then" decision represents a hesitation: " x is at least as good as y " or " x is not at least as good as y. "
Using decision rules, it always is possible to represent all common decision policies. For instance, let us consider the lexicographic ordering: the criteria considered are ranked from the most important to the least important. Between two objects, the object preferred with respect to the most important criterion is preferred to the other; if there is an ex aequo (a tie) on the most important criterion, then the object preferred with respect to the second criterion is selected; if there is again an ex aequo, then the third most important criterion is considered, and so on. If there is an ex aequo on all the considered criteria, then the two objects are indifferent. The lexicographic ordering can be represented by means of the following D≤ decision rules:
- If x is (at least) preferred to y with respect to criterion q 1, then x is preferred to y.
- If x is (at least) indifferent with y with respect to criterion q 1 and x is (at least) preferred to y with respect to criterion q 2, then x is preferred to y.
- If x is (at least) indifferent with y with respect to all the considered criteria except the last one and x is (at least) preferred to y with respect to criterion qn, then x is preferred to y.
- If x is (at least) indifferent with y with respect to all the considered criteria, then x is indifferent to y.
Induction of decision rules from information tables is a complex task and a number of procedures have been proposed in the context of such areas like machine learning, data mining, knowledge discovery, and rough sets theory. The existing induction algorithms use one of the following strategies: (a) generation of a minimal set of rules covering all objects from a information table; (b) generation of an exhaustive set of rules consisting of all possible rules for a information table; (c) generation of a set of "strong" decision rules, even partly discriminant, covering relatively many objects each but not necessarily all objects from the information table.
CREDIBILITY OF DECISION RULES
Decision rules also can be considered from the viewpoint of their credibility. From this point of view, the following classes of decision rules can be distinguished:
- Crisp, exact decision rules (i.e., the rules presented above whose "then" part is univocal).
- Crisp, approximate decision rules, induced from an inconsistent part of a data set identified using the rough sets theory; the "then" part of approximate decision rules specifies several possible decisions that cannot be reduced to a single one due to inconsistent information.
- Possible decision rules covering objects that may belong to the class suggested in the "then" part; the objects that may belong to a class are identified using the rough sets theory as objects belonging to so-called upper approximation of the class.
- Fuzzy decision rules induced from a vague or imprecise data set using the fuzzy sets theory. Informally, a fuzzy set may be regarded as a class of objects for which there is a graduality of progression from membership to non-membership: an object may have a grade of membership intermediate between one (full membership) and zero (nonmembership).
- Probabilistic decision rules covering objects from the class suggested in the "then" part (positive objects), but also objects from other classes (negative objects); the ratio between the positive objects and the negative objects should be at least equal to a given threshold.
APPLICATIONS
Decision rules have been used for description of many specific decision policies, in particular for description of customers' decisions. The most well known decision rules of this type are the association rules, whose syntax is the following: for p percent of times if items x 1 x 2 …, x n were bought, then items y 1 y 2 …, y m were bought as well, and q percent of times x 1 x 2 …, x n , y 1 y 2 …, y m were bought together. For example, 50 percent of people who bought diapers also bought beer; diapers and beer were bought in 2 percent of all transactions.
The following example illustrates the most important concepts introduced above. In Table 1, six companies are described by means of four attributes:
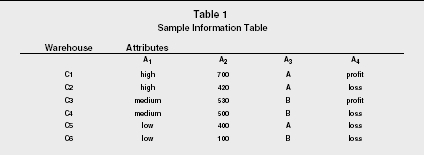
Sample Information Table
| Warehouse | Attributes | |||
| A 1 | A 2 | A 3 | A 4 | |
| C1 | high | 700 | A | profit |
| C2 | high | 420 | A | loss |
| C3 | medium | 530 | B | profit |
| C4 | medium | 500 | B | loss |
| C5 | low | 400 | A | loss |
| C6 | low | 100 | B | loss |
- A 1 capacity of the management
- A 2 number of employees
- A 3 localization
- A 4 company profit or loss
The objective is to induce decision rules explaining profit or loss on the basis of attributes A 1 A 2 and A 3 Let us observe that:
- Attribute A 1 is a criterion, because the evaluation with respect to the capacity of the management is preferentially ordered (high is better than medium and medium is better than low).
-
Attribute A
2
is a quantitative attribute, because the values of the number of
employees are not preferentially ordered (neither the high number of
employees is generally better than the small number, nor the inverse).
Similarity between companies is defined as follows: Company A is similar
to Company B with respect to the attribute "number of
employees" if:
- Attribute A 3 is a qualitative attribute, because there is not a preferential order between types of localization: two companies are indiscernible with respect to localization if they have the same localization.
- Decision classes defined by attribute A 4 are preferentially ordered (trivially, profit is better than loss).
From Table 1, several decision rules can be induced. The following set of decision rules cover all the examples (within parentheses there are companies supporting the decision rule):
Rule 1. If the quality of the management is medium, then the company may have a profit or a loss (C3, C4).
Rule 2. If the quality of the management is (at least) high and the number of employees is similar to 700, then the company makes a profit (C1).
Rule 3. If the quality of the management is (at most) low, then the company has a loss (C5, C6).
Rule 4. If the number of employees is similar to 420 and the localization is B, then the company has a loss (C2).
Decision rules are based on elementary concepts and mathematical tools (sets and set operations, binary relations), without recourse to any algebraic or analytical structures. Principal relations involved in the construction of decision rules, like indiscernibility, similarity, and dominance, are natural and non-questioned on practical grounds. Decision rule representation of knowledge is not a "black box," or arcane methodology, because the rules represent relevant information contained in data sets in a natural and comprehensible language, and examples supporting each rule are identifiable. Because contemporary decision problems are associated with larger and larger data sets, induction of decision rules showing the most important part of the available information is increasingly in demand.
SEE ALSO: Decision Making ; Decision Support Systems
Salvatore Greco ,
Benedetto Matarazzo , and
Roman Slowinski
Revised by Wendy H. Mason
FURTHER READING:
Agrawal, Rakesh., Tomasz Imielinski, and Arun Swami. "Mining Association Rules Between Sets of Items in Large Databases." In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data. New York: ACM Press, 1993.
Greco, S., B. Matarazzo, and R. Slowinski. "The Use of Rough Sets and Fuzzy Sets in MCDM." In Advances in Multiple Criteria Decision Making. ed. T. Gal, T. Hanne, and T. Stewart. Dordrecht/Boston: Kluwer Academic Publishers, 1999.
Hu, Xiaohua, T.Y. Lin, and Eric Louie. "Bitmap Techniques for Optimizing Decision Support Queries and Association Rule Algorithms." Proceedings of the 2003 International Database Engineering and Applications Symposium. Hong Kong: SAR, July 2003.
Luce, R.D. "Semi-Orders and a Theory of Utility Discrimination." Econometrica 24 (1956): 178–191.
March, J.G. "Bounded Rationality, Ambiguity, and the Engineering of Choice." In Decision Making: Descriptive, Normative, and Prescriptive Interactions. ed. David E. Bell, Howard Raiffa, and Amos Tversky. Cambridge New York: Cambridge University Press, 1988.
Michalski, R.S., Ivan Bratko, and Miroslav Kubat, eds. Machine Learning and Data Mining: Methods and Applications. Chichester: J. Wiley & Sons, 1998.
Pawlak, Zdzislaw. Rough Sets: Theoretical Aspects of Reasoning about Data. Dordrecht/Boston: Kluwer Academic Publishers, 1991.
Pawlak, Zdzislaw, and Roman Slowinski. "Rough Set Approach to Multi-Attribute Decision Analysis." European Journal of Operational Research 72 (1994): 443–459.
Peterson, Martin. "Transformative Decision Rules." Erkenntnis 58, no. 1 (2003): 71–85.
Slovic, P. "Choice Between Equally Valued Alternatives." Journal of Experimental Psychology, Human Perception and Performance 1, no. 3 (1975): 280–287.
Slowinski, R. "Rough Set Processing of Fuzzy Information." In Soft Computing: Rough Sets, Fuzzy Logic, Neural Networks, Uncertainty Management, Knowledge Discovery. ed. T.Y. Lin and A. Wildberger. San Diego: Simulation Councils Inc., 1995.
Slowinski, Roman, ed. Fuzzy Sets in Decision Analysis, Operations Research, and Statistics. Dordrecht/Boston: Kluwer Academic Publishers, 1998.
Slowinski, R., and J. Stefanowski. "Handling Various Types of Uncertainty in the Rough Set Approach." In Rough Sets, Fuzzy Sets and Knowledge Discovery. ed. W.P. Ziarko. London: Springer-Verlag, 1994.
Stefanowski, J. "On Rough Set Based Approaches to Induction of Decision Rules." In Rough Sets in Data Mining and Knowledge Discovery, Vol. 1. ed. L. Polkowski and A. Skowron. Heidelberg: Physica-Verlag, 1998.
Tversky, A. "Features of Similarity." Psychological Review 84, no. 4 (1977): 327–352.
Zadeh, Lofti. "Fuzzy Sets." Journal of Information and Control 8 (1965): 338–353.
Comment about this article, ask questions, or add new information about this topic: